株式会社ブロードは企業のIT運用の効率化とセキュリティ向上を支援しています。
![]()








Swimでイベントストリームのデータフローパイプライン自動構築
Swimブログ 2022年1月7日 Simon Crosby記
ブローカはアプリケーションを実行しません。ブローカは現実社会とそのイベントを分析するアプリケーションとの間のバッファーです。イベントストリームプロセッサ(ApacheKafka/Pulsarの用語では)またはデータフローパイプラインはイベントスキーマを与えられたと仮定し、そのスキーマを継続的に分析し知見(インサイト)を引き出すアプリケーションです。このようなアプリケーションはステートフルである必要があります:システムモデルを継続的に修正し、そのシステムの事前の状態のデータソース部分に関する変化による影響を分析した結果からのインサイトを提供します。どのような有用な分析にも過去の知識が必要で、多くのイベントにまたがるあるいはデータソースにまたがります。イベント分析のためにデータフローのパイプライン構築をすることがストリームプロセッシングアプリケーション構築の目的です。
異なるツールセットがアプリケーション構築のしやすさや、ストリームプロセッサーが提供できるインサイトの品質に影響します。アクターモデル(Swim、Akka)はApache Flink などを利用したDevOps-y Micro-Service-yアプローチ、またはイベント分析目的のstreaming SQLベースアプローチに比べ有利です。それらは以下の理由からです:
- Swimのアクターランタイムは動的にアクターを作成、お互いを連携させてイベントを処理することにより、イベントストリームから直接取得するステートフルなデータフローパイプラインを構築します。
- データソース間の関係は関連するアクター同士を対話させることにより容易にアクターパラダイム内でモデル化可能です:Akka経由ではメッセージパスですがSwim経由では動的リンクです。
- 現実の世界を理解することは常に複数のデータソースの変更の連携された状態を検知することを含みます、時に時間/空間(例えばお互いが相関しているか、地理的に「近いか」など)。動的に関係しているアクターは(変更が起こる都度)検知されランタイムにより繋がれ、システムモデルを構築します、その瞬間にです。
- 深度のあるインサイトは連携された変更の影響を見つけ出し、評価することに常に依存します。交差点にあるすべてのセンサーや近隣の交差点にまたがるリアルタイム学習を利用した学習交通はその正確性が向上します。
センサーがその状態を変更するとこれは自身の交差点の予測および近隣の全ての交差点の予測を変更します。
データソース間のロジックや数学または学習(別の意味での数学)に依存するアプリケーションはシステムのステートフルなモデルが必要です。何らかのデータベースが各々のデータフローパイプラインの核にあることも一般的です。更新にともなう遅延はデータベースの往復時間によります、これはCPUとメモリーより何百万倍も遅くなりますが、この遅延以上に面倒な課題があります:もしイベントがデータベースの更新を駆動するなら、その結果の分析をトリガーし実行するのは何でしょうか?明確にいうと、アプリケーションが状態の変更をレポートするイベントを受けたときソースのデータベースの行を更新するのは容易です、しかしシステム上の変更の影響の演算―依存性の結果―は不可能です。なぜならデータベースはこれら要素を保管しないからです。時間-および時間にわたる行動-はどのような動的なシステムを理解する際にも重要な役割を果たします、そしてデータベース(時間軸にまたがるデータベースも含む)は分析には役にたちません。
ストリーム処理プラットフォームによって構築あるいは実行可能なタイプのアプリケーションはプラットフォームがストリーム、状態の演算、時間の演算管理をどのように管理するかにより制約されます。またプラットフォームがサポートする演算の豊富さ―トランスフォームがどう実現できるか―と分析中のコンテクスト認識、これはある種類の演算のパフォーマンスに多大に影響する―を考慮する必要があります。
ステートフル分析に関してここで挙げるポイントには二つのアプローチがあります。ストリーミングデータから直接、データフローパイプラインを瞬時に構築できるアクターモデルの「強力な機能」について時間を割いて言及する前に、ステートフル分析に関する二つのアプローチのポイントを挙げます。
Apache Flink
Apache Flinkはバインドされたあるいはバインドされていないデータストリーム上のステートフル演算のための分散プロセスエンジンです。ストリーミングデータに関しては、SwimとFlinkは以下の分析をサポートします。
- バインドされたあるいはされないストリーム:ストリームサイズは固定でもエンドレスでも対応
- リアルタイムまたは記録されたストリーム:データを処理するにはふたつの手法があります―「瞬時」または「保管し分析」。両方のプラットフォーム(Apache FlinkとSwim)ともに両方のシナリオをサポートします。Swimは保存されたストリームを再生できますが、その方法では記録されたストリームにとってイベント時間が何を意味するか?、といった解釈に影響すると考えます、さらにストリームを再生するために取得する、=ストーレッジにアクセスするのが非常に遅いことも難点と考えます。
Swimは分析の前にデータを保存しません―データが受信されたその瞬間に演算がおきます。Swimはまた分析後の生データの保存に関しては無関心です:デフォルトではSwimは分析されメモリ内のステートフル状態になると、対象の生データを廃棄します。しかし必要があれば保存もできます―分析後、学習後および予測後に。Swimはデータソースごとのストリームをサポートします―これはブローカ世界でのトピックかもしれませんが、―何億というストリームも管理可能です。Swimはブローカを要しません、でもブローカからのイベントを消化可能です、反してFlinkはこれをサポートできません。
全ての有用なストリーミングアプリケーションはステートフルです。(イベントにシンプルな移行を適用するアプリケーションのみがステートを要しません―例えば「ストリーミングトランスファーとローディング」型など)ビジネスロジックを実行するアプリケーションは後程の演算に利用アクセスするために中間の結果を記憶する必要があります。SwimとFlinkの主要な違いはどのような演算に、可用なステートが何かということです。
これがSwimその他のアプリケーションから抜きんでているポイントです:
Flinkでは各イベントおよびイベント間で過去に保持されたステートで解釈されたものはそのイベント(とタイプ)のみに関連付けされます。イベントはステートフルな機能(およびアウトプットはイベントの順序の移行です)を使って解釈されます。良い例はカウンターまたはイベントシリーズ上の平均値を演算することです。
各々の新しいイベントは直前のイベントの演算の結果に依存する演算を駆動します。
The Actor Model | アクターモデル
SwimOS(Apache 2.0 OSS)- はストリーミングイベントデータから切れ目ないインテリジェンスを提供するストリームプロセッサーです。例としてはKafkaおよびパブリックデータを利用した衛星追跡アプリです。(こちら)
SwimOS
- ストリームデータを瞬時にステートフルに処理するアプリケーションの開発を容易にします。このようなものには可視化、アプリケーションと常駐性、分析、学習および予測を「分析、実行、そして保存」アーキテクチャで行う高度な解像度の高い知見を提供します。
- イベントの頻度および演算の複雑性など現実のリアルタイム処理要件に基づき、自動でアプリケーションの基盤をスケーリングします。
- Javaのエクステンションで2MBのものです(GraalVMをランタイムで利用します)
- 非常に高速です!従ってリアルタイムでの分析、学習および予測をメモリ内のステートフルプロセス利用で実現します。
SwimOSは「分析、実行、そして保存」アーキテクチャを利用します。:これにより切れ目ない分析と予測をメモリ内で可能にします、追加のデータ保管必要はありません。インサイトは切れ目なく可用で―リアルタイムの応答を実現します。
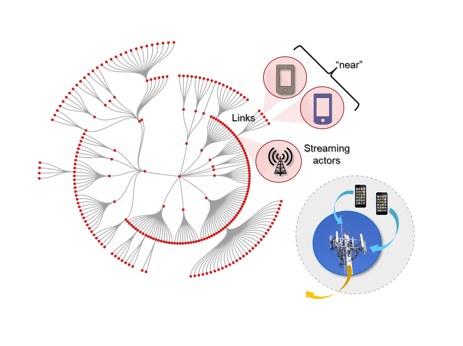
開発者は簡単なオブジェクト指向のアプリケーションをJavaで作成し―SwimOSがストリーミングデータを利用してステートフルな同時進行のアクターのグラフを構築します―データソースの「デジタルツイン」であるWeb Agentsと呼びます。通常各々がKafkaトピックに呼応します。各アクターは単一のソースからのイベントデータを処理しその状態をメモリー内に保持します。データ内で検知されたコンテクストにそってお互いを繋げます。至近距離、包含、相関性などのようなソース間のコンテクストベース関係を反映し、動的にグラフを構築します。これらの関係性は開発者によって指定可能です(例えば信号機、ループ、歩行者用押しボタンなどのある交差点)。しかしデータはグラフを構築します:自身の状態をレポートすると相互間にはリンクが張られます。結果のグラフは「モノのLinkedIn」のような感じです:現実資産のデジタルツインであるアクターは動的にリンクされグラフを構成し、これはデータ内で検知された現実の世界の関係性に基づきます。リンクされたエージェントはリアルタイムでお互いの状態の変更を察知します。
Web agents は自身の状態とリンクされた他のエージェントの状態から継続的に分析、学習および予測しUIやブローカ企業アプリケーションに詳細な知見をストリームします。SwimOSはメモリ内、ステートフル、同時進行の演算から恩恵を受けます。主要な分析、学習および予測のストリーミング展開アルゴリズムはSwimOS内に内蔵されていますがSpark上のアプリケーションとのインターフェースを取るのも容易です、Sparkストリーミングの小さいバッチをメモリ内、ステートフルなWeb Agentグラフと置き換えることになり、直接RDDをSparkに提供しアプリケーションの簡素性を大いに向上することが可能になります。
我々はSwimOSを利用して通信企業向けにアプリケーションを構築しました、これは何千もの通信塔、その配下に何千万もの携帯契約者がつながる、からの一日あたり5PBのストリーミングデータを継続的に収集、分析するものです。アプリケーションは通信会社が常に通信環境品質を最適化し、カスタマーエクスペリエンスを保証することを実現します。このアプリケーションは2,000-3,000ほどのJavaコードですがSwimOSによるランタイムグラフは40のインスタンスにわたります。